Technische Universität Wien
Orientation and Processing of Airborne Laser Scanning data
Department of Geodesy and Geoinformation - Research Groups Photogrammetry and Remote Sensing
To process large amounts of data using multiple computers/machines, opals uses the ipyparallel framework. To see how to set up ipp (ipypyarallel) controllers and engines, please see the documentation of multi machine processing in opals using opalsTask.
Due to the fact that multiple machines are involved in the processing, the input files need to be accessible for every participating computer. In order to make use of the local processing power, the input files necessary for a certain task should be copied to a temp directory of the assigned machine, then computed locally and finally copied back to the shared network. In opals, opalsTask was implemented to handle the above described process of creating temp directories and copying files in the background. Within opalsTask, there are Jobs and Tasks, which will be explained in the next sections.
The following code should demonstrate how to use opalsTask in order to create an opals workflow script that can be excecuted and distributed to multiple machines. The prerequisite for the following code to work is that an ipp controller as well as engines are set up as described here.
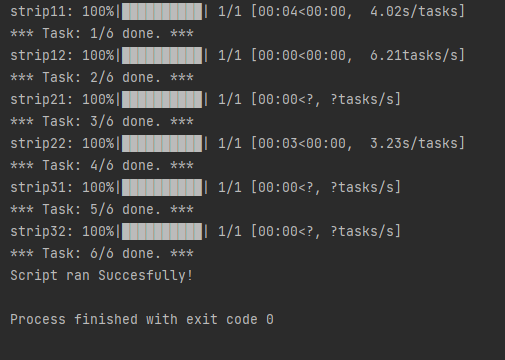
When running this script, the 6 tasks (one for each input strip file) are distributed among the engines by the controller and then executed. In Figure 1, one can see that this particular engine handled tasks 1 and 5, the module runs for strip11 and strip31, respectively. The python output of the DemoWorkflowScript run can be seen in Figure 2.

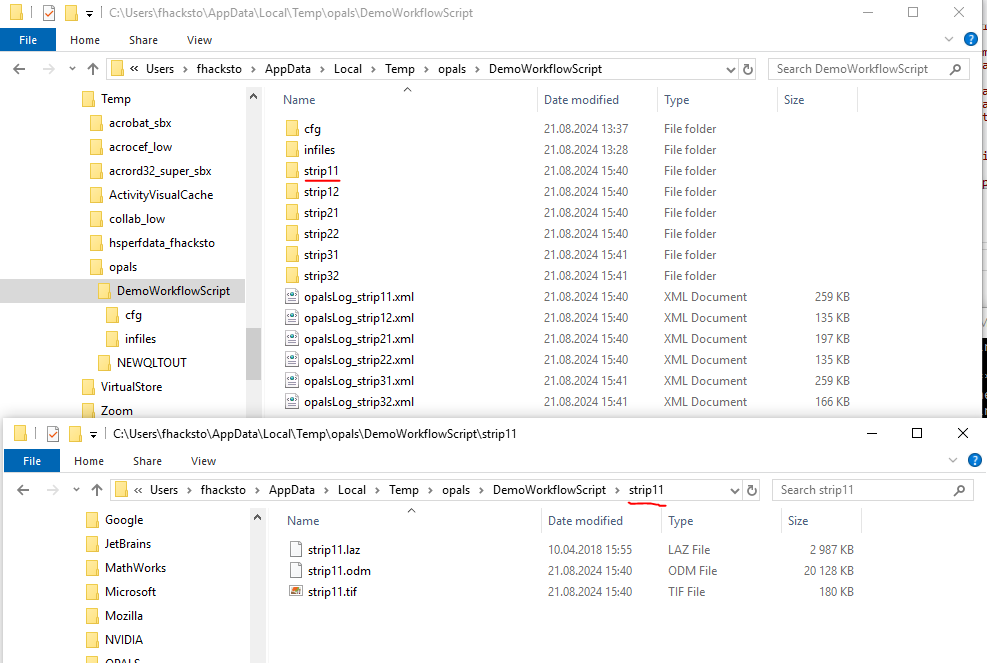
In Figure 3, the temp folder where the processing happens is depicted. One can see that the processing happens in a sort of "flatmode" where all the outputfiles of a task are in the same folder.
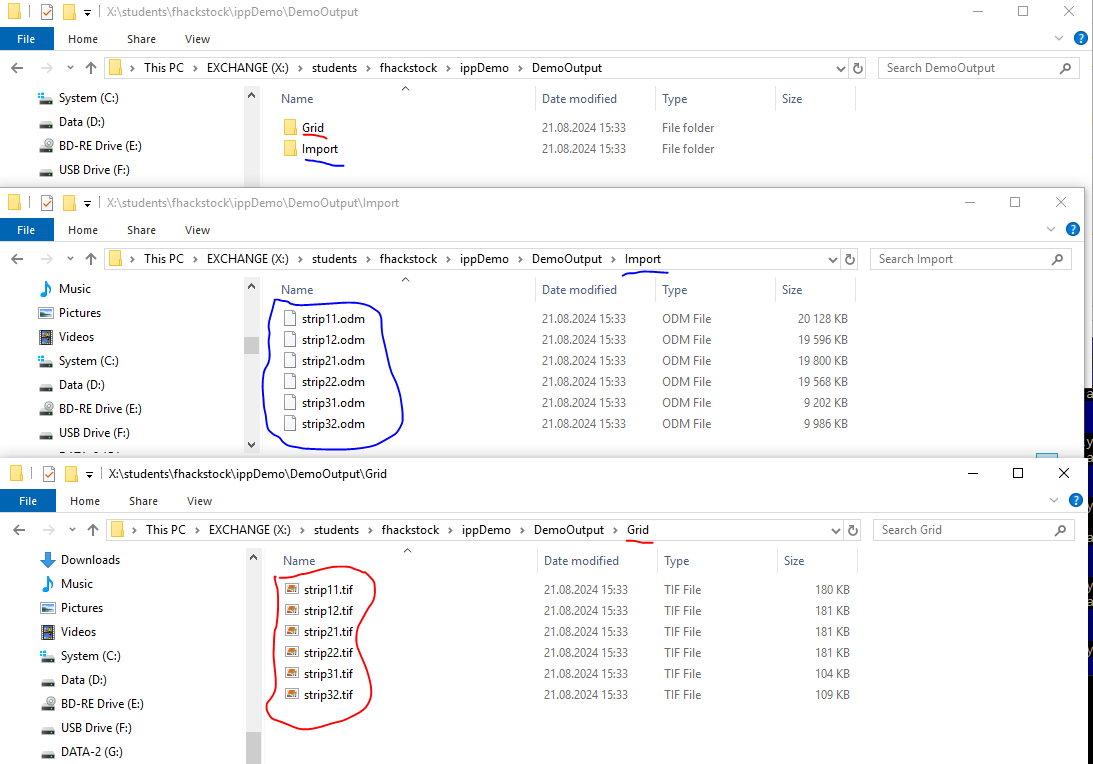
In our case we want all the Import results and Grid results in their own folders, which is what is depicted in Figure 4.
While the script above provides information about how to set up a workflow script to execute tasks, some background information about opalsTask might be interesting. A job has the main function to prepare the temp folder on a given machine and copy relevant files such as cfg or job infiles. We call this the Job Prephase . In case a task has been run on a certain machine, the job folder has already been created and the Job Prephase is therefore skipped. Every task also has a Task Prephase , where the task folder within the job folder is created and the task infile is copied. In the so called Task Mainphase all the opals modules of a task are simply excecuted one after the other. Finally in the Task Postphase , the output files are copied to the final destination and the task directory is emptied in order to save disc space. So whenever a task is executed, the phases are run in the following order:
 1.8.17
1.8.17